
PathNet: Path-Selective Point Cloud Denoising
Abstract
当前的点云降噪(PCD)通常依赖于单一网络,试图训练参数来适应每个点云的噪声,单丝忽略了不同噪声程度和几何结构可能各异。
- 基于强化学习(RL),基于路径选择(Path-Selective)
- 动态选择最合适每个点的去噪路径
创新点:
- 首次在去噪任务中引入几何感知和噪声感知的奖励函数,训练RL中的路由代理,使其聪明地选择去噪路径
- 路由代理和去噪网络是联合训练的,从而有效避免了过度平滑或去噪不足的问题
1. Introduction
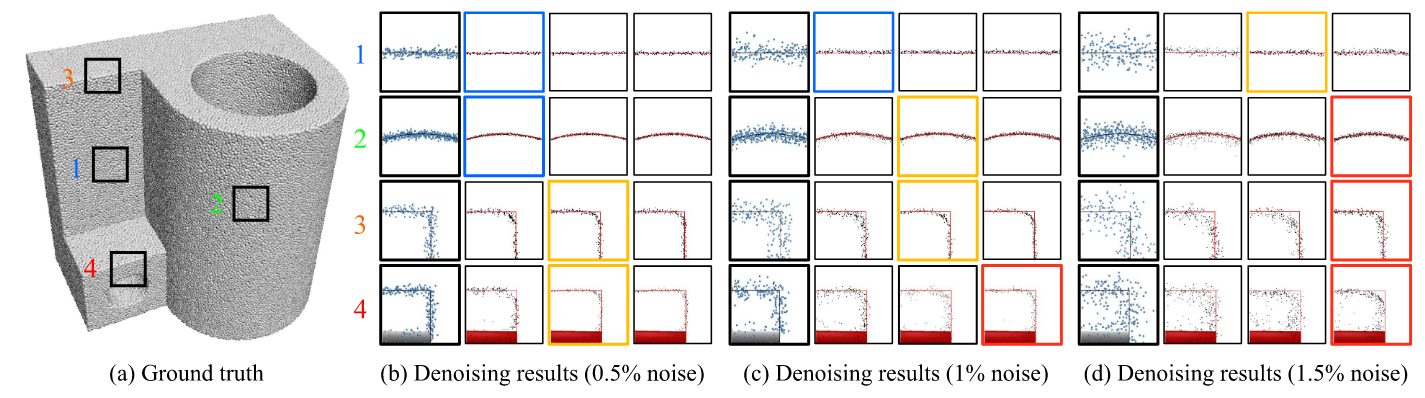
在(a)中选取了四个区域,分别对应(b)-(d)中的四行,表示四种情况:平坦、弯曲曲面、锐利。而也有不同的噪声进行测试,可以对于每一种噪声都有三个情况进行比较,分别是使用1、3、5个去噪块。最佳情况用有颜色的方框进行表示,蓝色表示1个去噪块最佳、黄色表示3个去噪块最佳、红色表示5个去噪块最佳
可以看出,对于低噪声的时候,我们不需要那么多的去噪块,而高噪声的时候则没有蓝色的方框,即使用更多的去噪块更佳。
✅核心优势:
为每一个点动态选择最合适的网络路径
作者受到图像修复任务的启发,把PCD作为一个逐点决策的问题,每个点选择不同的“去噪路径”,由智能体(Agent)动态选择
3. Method
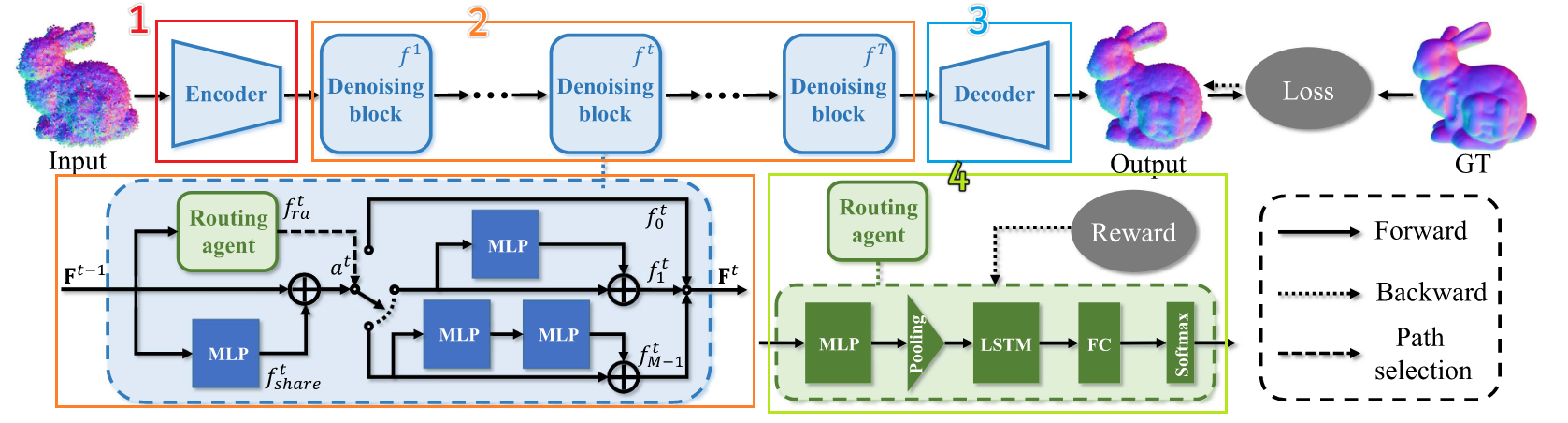
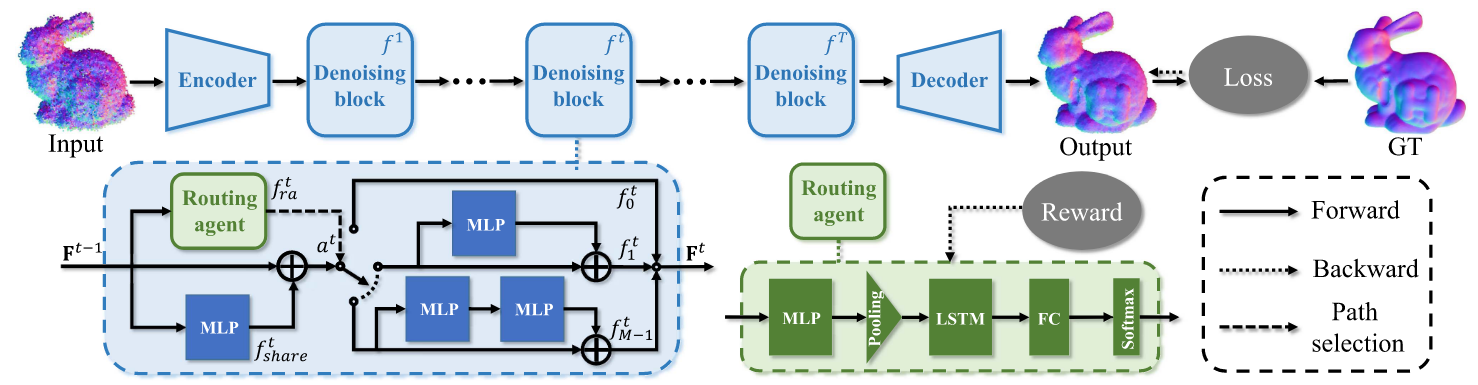
分成四个部分,分别是Encoder编码器、Denoising Block去噪模块、Decoder解码器、Routing Agent路由选择器(绿色)
1️⃣Encoder编码器
编码器就是将特征学习到高维的层面,对于带噪声的点云\hat{P}
- 归一化到单位球内
- 每个点建立一个局部patch
- 使用两层图卷积网络,这里叫Patch-Graph Module
输出是每个点的初始特征\mathrm{F}^0
\mathrm{F}^0=\text{MLP}(\text{cat}(\textcolor{red}{\max (}\textcolor{blue}{\text{MLP}(\mathrm{G}_1)}\textcolor{red}{)},\text{MLP}(G_2)))
局部特征
G_1的最大值和全局结构的G_2特征进行拼接继续学习
2️⃣Denoising Block去噪模块(重点)
一共T个,每个去噪模块进行特殊设计
模块内有三个部分:
- 共享子网络
f_{share}^t:每个点都经过这个基础特征提取 - 去噪路径子网:包含不同的路径
- 路由agent
f_{ra}^t:根据当前点决定走哪个
\mathrm{F}^t=f_{a^t}^t(f_{share}^t(\mathrm{F}^{t-1})), \quad 1\leq t\leq T
这里a^t是agent选择路径的编号,有路径f_0^t,f_1^t,\cdots,f_{M-1}^t,一般设置M为2
3️⃣Decoder解码器
这里是用于预测位移矢量
从最后一个去噪块\mathrm{F}^T得到每个点的特征,通过max pooling和两个全连接层预测位移向量ε^t,最终获得去噪点云\mathrm{P}^t=\hat{\mathrm{P}}-ε^t
4️⃣Routing Agent路由选择器
状态、动作和奖励的定义
-
状态(
s^t):在每个去噪块中,状态由当前点的特征以及历史信息(通过 LSTM 捕捉的特征)组成。 -
动作(
a^t):动作是代理选择的去噪路径。PathNet 有多个去噪路径,代理需要从这些路径中选择最合适的一条。 -
奖励(
r^t):奖励用于指导代理学习最优的去噪路径选择。奖励的大小反映了代理所选路径的好坏,主要依据去噪效果来判断。
\pi^t(a\mid s^t)=f_{ra}^t(s^t)
左式表示在给定状态s^t下选择动作a的概率,在训练阶段,代理通过采样来探索更多的路径选择,而在测试阶段代理会选择概率最大的路径
奖励的获取:
-
在选择一个动作
a^t后,代理会获得一个奖励r^t,这个反应当前路径选择的质量 -
代理目标是通过强化学习最大化累计奖励
R=\sum_{i=1}^Tr^t
代理的结构:PathNet 中的路由代理由以下几个模块组成:
- 多层感知机(MLP):用来处理输入特征;
- 最大池化层(Max Pooling):帮助减少特征的维度;
- LSTM 模块:用于捕捉不同去噪块之间的历史特征,学习去噪路径之间的相关性。
- 全连接层(FC):进一步处理特征信息;
- 激活函数(Softmax):用来输出每个路径选择的概率分布。
作者将路径选择过程视作 马尔可夫决策过程(MDP),并通过 强化学习 来训练代理。
我有自己的理解:
问题 回答 Q1:选了路径后,怎么知道好坏?还会换吗? 不换路径,继续前向传播到下一层,reward 通过最终去噪效果评估 Q2:怎么调整策略?何时调整? 每轮训练结束后,利用 reward 通过策略梯度更新路径选择策略 Q3:每层的路由器是否共享? 不共享,每个去噪块 f^t都有独立的 Routing Agentf^t_{ra},只有f_{share}^t是共享的
损失函数
损失函数主要分为两个部分,分别是去噪损失和排斥损失
-
去噪损失:当然是鼓励尽可能接近Ground Truth
-
排斥损失:用于减轻去噪之后点云某些点过于聚集
L^t_r=\Vert \mathrm{p}^t-\mathrm{p}_f\Vert_2^2
\mathrm{p}_f是当前去噪点\mathrm{p}^t在真实点云中的最远点,即这个点与去噪点的距离最大(这里不是很懂为什么最远点的距离要作为损失函数可以让点不聚集?)