概括 & 介绍
论文链接🔗:https://ojs.aaai.org/index.php/AAAI/article/view/32667
代码链接🔗:https://github.com/hapifuzi/spu-imr
这篇是自监督的文章,无需ground truth。通用也是任意尺度,核心在于迭代式掩码恢复网络
他们提出将点云视为一个全局形状补全的问题,不再是点和点之间进行找点,而是把缺失的部分“画”出来。具体而言,
- 分块:点云分patches
- 掩码(Mask):随机移除一部分完整的面片,只保留可见的patch
- 恢复(Recover):训练一个神经网络,仅根据可见patch,去预测和补全缺失的那部分
如何实现上采样?
- 在测试/推理阶段,选择不同的掩码序列,可以让网络反复地“补全”物体的不同部分
- 每一个补全都会生成一个完整的、可能是稠密的面片
- 最后这些被补全、恢复出来的面片合并在一起,就得到了一个最终的足够稠密的上采样点云
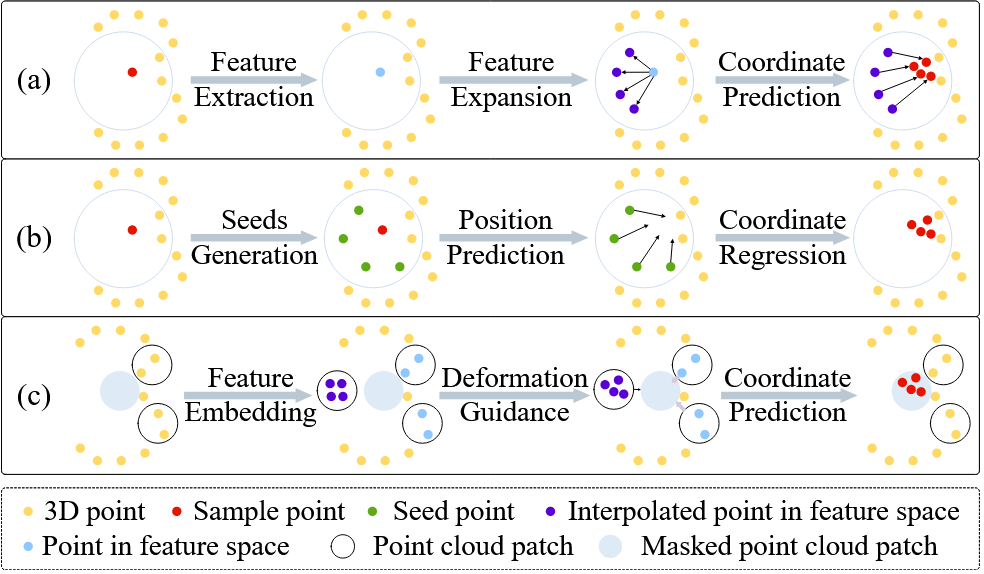
- (a)基于特征空间的插值。点转化为特征,然后在特征空间进行扩展,再变回三维坐标
- (b)基于点云插值。在周围生成一些种子点,再做投影进行坐标回归【ab二者由内而外的插值思想】
- (c)就是本文的补全思想。遮掩一部分,观察可见的patch了解形状和结构。【由外而内】
本篇受到2022年Point-MAE的启发,做出了以一种自监督的方式提出了迭代的mask恢复网络。
📌更具体的流程如下:
- 首先进行分块
- 给定一个“掩码序列”,隐藏掉一部分的面片
- 生成“可学习的”初始面片。对于每一个被掩码覆盖的区域,网络先随机生成一个可学习的面片,作为初始的“画布”
- 迭代式恢复变形(Iterative Deformation):这是核心。在两个信号的引导下,网络会迭代地、逐步地将这个随机生成的毛坯变成正确的形状:
- 引导信号1 —— 位置编码:被掩盖patch的中心点位置编码。告诉网络我应该在哪里画出来。
- 引导信号2 —— 上下文特征:所有可见面片的特征。告诉网络周围的形状长什么样
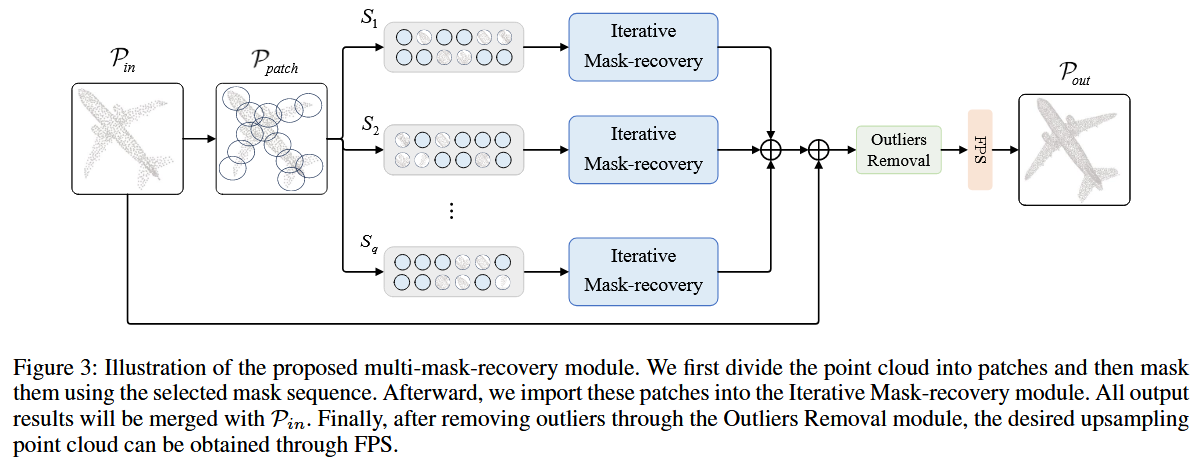
📌而在任意尺度上采样的实现过程中,使用到了MMR模块,也就是多掩码恢复模块:
- 核心思想在于进行多次、不同模式的“完形填空”来生成足够稠密的点云,然后再从里面进行采样
- 具体步骤:
- 在测试的时候,使用多种不同掩码模式,反复地对输入点云进行“挖空 - 填补”操作
- 每次都会生成一组完整的patch,将所有轮次生成的所有patch进行合并,得到了一个点个数非常多的点云
- 最后在这个“超密度”的点云上面使用最远距离采样(FPS)得到任意数量的点云。
💡会将掩盖掉patch然后生成出来这个部分的patch作为数据进行下一步操作吗?
我认为不会。因为这是预测出来的结果,将预测出来的结果再去做预测无疑会放大结果。
方法
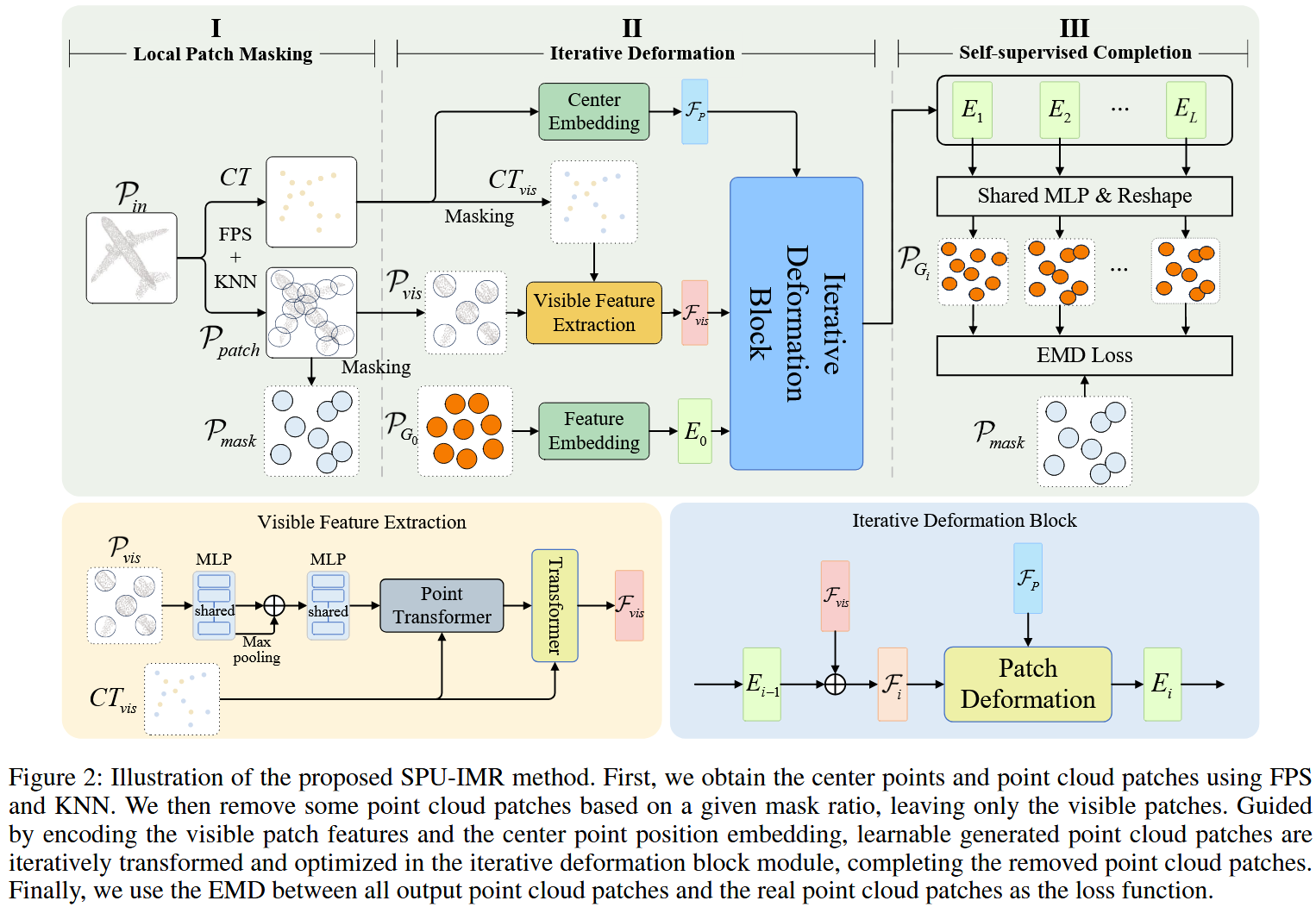
首先整个分成了三个部分。分别是I. 局部面片掩码,II. 迭代式变形,和 III. 自监督补全
阶段一:局部面片掩码 (Local Patch Masking)
对于点云使用最远距离采样和KNN得到中心点CT和分成的patch\mathcal{P}_{patch}。再通过\mathcal{P}_{patch}进行掩码操作,可以得到可见的\mathcal{P}_{vis}和被掩码的\mathcal{P}_{mask}。最后生成了“毛坯”\mathcal{P}_{G_0}。
阶段二:迭代式变形 (Iterative Deformation) - 模型核心引擎
这是核心部分,目标是利用已知信息,把毛坯\mathcal{P}_{G_0}变成正确的形状。
-
提炼上下文特征
\mathcal{F}_{vis}首先处理可见面片
\mathcal{P}_{vis},正如左下角所示,通过MLP、最大池化、最后送入一个transformer模块进行学习。(虽然我还不太了解point transformer)transformer可以捕捉不同元素之间的长距离依赖关系,作用充分理解这些零散的不完整的面片。最后得到强大的上下文特征向量\mathcal{F}_{vis} -
准备“待恢复”特征
E_0和F_P- 特征
E_0:将随机生成的毛坯通过一个特征嵌入网络,得到初始特征表示 - 特征
F_P:将被掩码的patch的中心进行编码,得到位置特征F_P,这个特征告诉网络,要恢复的那个块大概的位置在哪
- 特征
-
进入迭代变形模块 (Iterative Deformation Block):
这是一个迭代模块,正如右下角所示,每次将上一轮得到的特征
E_{i-1}结合全局上下文特征F_{vis}和位置特征进行融合(concat)。每次都需要加上F_P提醒位置。送入patch deformation模块得到新特征E_i
阶段三:自监督补全 (Self-supervised Completion)
这个阶段就是“交卷”和“评分”的阶段了
-
生成最终坐标
P_{G}。经过L次迭代之后,将每次的特征E_i都进入一个共享MLP和reshape模块,高维特征解码至三维坐标,得到最终坐标(依赖loss) -
计算损失(EMD Loss)
将之前被掩码覆盖的
\mathcal{P}_{mask}拿出来计算损失,也就是P_G和\mathcal{P}_{mask}之间的差异 -
反向传播
其实这张图已经讲完了所有了,我觉得都不需要往下看了,但是还是讲一下其他的细节部分。
- 【阶段1】在每个patch送入网络之前会将坐标进行归一化,也就是将目标点送入到(0,0,0),这样目的是学习形状和结构,而不是绝对位置(位置无关性)。
- 【阶段1】面片重叠(Overlapping patches)。FPS选择的时候会有重叠部分,这不要紧,这样可以获得更丰富连续的上下文信息。
- 【阶段2】提取上下文特征
\mathcal{F}_{vis}的时候,进入了PointTr和另一个Tr的模块(和Transfomer相关),模块增强(具体见原文) - 【阶段2】Patch Deformation模块也有强大的Transformer来完成的
- 【阶段2】每一轮迭代之后使用LayerNorm,稳定训练。
- 【阶段3】公式7和9可以看出迭代每一层
i(1\leq i\leq L)的时候,都会生成一次预测坐标P_{G_i},立马计算损失,最终的损失是L迭代损失之和。不仅要求结果最好,里面的路径每次也都要有意义 - 【阶段3】为什么使用EMD。防止过拟合或聚类,挤在一起;保持拓扑结构
在任意尺度上进行上采样
步骤一:多掩码恢复。将q个不同序列进行q次补全操作,得到q组恢复出来的面片
步骤二:合并。注意也要与原始点云进行合并。
步骤三:后处理和采样。处理一次离群点,最后再FPS采样。