
private,shared,default子句
在 OpenMP 中,private、shared 和 default 是循环子句中常用的修饰符。它们用来指定循环变量的存储类型,以便在并行执行时确保数据一致性。
private子句指定循环变量为私有变量。在并行执行时,每个线程都会有一个私有的副本,不会与其他线程共享。私有变量的值在进入循环时被初始化,在退出循环时被丢弃。shared子句指定循环变量为共享变量。在并行执行时,每个线程都会使用同一个变量,并且可以对它进行读写。共享变量的值需要在循环之外进行初始化,并且在循环执行完毕后可以继续使用。default子句指定循环变量为默认类型。如果没有指定private或shared子句,则默认为共享变量。
schedule
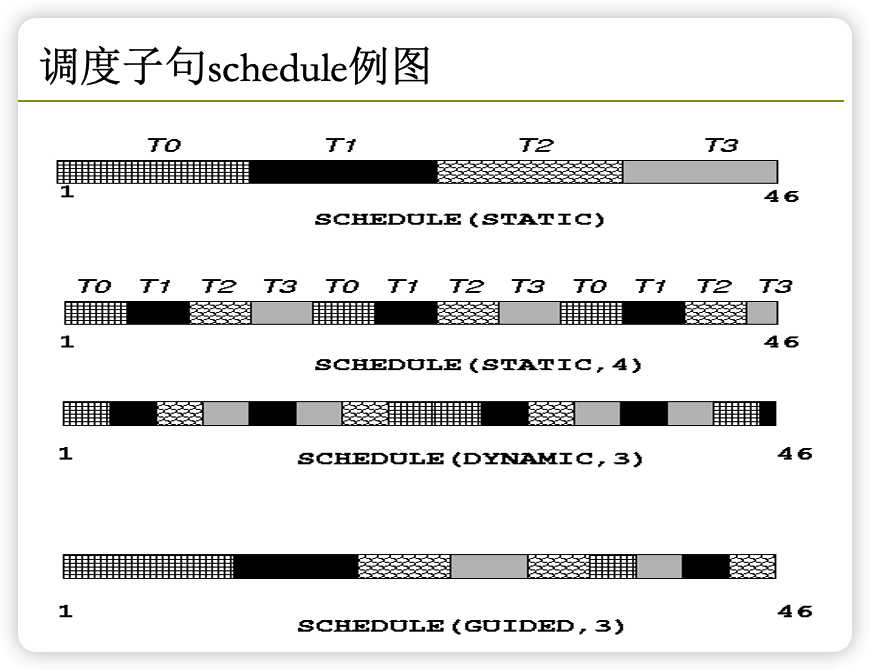
schedule 是 OpenMP 中用于指定并行循环调度策略的子句。它可以用来控制线程在循环中的工作分配,以提高程序性能。
static和dynamic
OpenMP 提供了四种调度策略:静态均匀分配、静态不均匀分配、动态均匀分配和动态不均匀分配。
static均匀分配将循环划分为若干个相等的块,并将每个块分配给一个线程。这种调度方式适用于循环迭代次数可以预先确定的情况。static, chunk_size不均匀分配与均匀分配类似,但它允许指定块的大小。这可以提高性能,因为线程可以一次性处理多个迭代。dynamic均匀分配会动态地将循环划分为若干块,并将块分配给不同的线程。这种调度方式适用于循环迭代次数不能预先确定的情况。dynamic, chunk_size不均匀分配与动态均匀分配类似,但它允许指定块的大小。这可以提高性能,因为线程可以一次性处
动态调度时,size小有利于实现更好的负载均衡,但是会引起过多的任务动态申请的开销,反之size大则开销较少,但不易于实现负载平衡。需要权衡
举例static:
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
int main() {
int num_threads = 2;
omp_set_num_threads(num_threads);
int i = 0;
#pragma omp parallel
{
#pragma omp for schedule(static)
for (i = 0; i < 10; i++) {
int tid = omp_get_thread_num();
printf("tid = %d, i = %d\n", tid, i);
}
}
return 0;
}
输出为:
tid = 0, i = 0
tid = 0, i = 1
tid = 0, i = 2
tid = 0, i = 3
tid = 0, i = 4
tid = 1, i = 5
tid = 1, i = 6
tid = 1, i = 7
tid = 1, i = 8
tid = 1, i = 9
由于我们使用了均匀分配调度策略,循环的每个迭代都会被分配给一个线程处理。由于我们有两个线程,所以每个线程将处理 5 次迭代。
通过查看输出,可以发现每个线程处理的迭代是相对连续的。这是因为静态均匀分配调度策略将循环划分为若干个相等的块,并将块分配给不同的线程。每个线程都会处理它负责的块中的所有迭代,所以迭代是相对连续的。
如果是static,3则答案是:
tid = 0, i = 0
tid = 0, i = 1
tid = 0, i = 2
tid = 0, i = 6
tid = 0, i = 7
tid = 0, i = 8
tid = 1, i = 3
tid = 1, i = 4
tid = 1, i = 5
tid = 1, i = 9
如果是dynamic则可能是下列答案
tid = 0, i = 0
tid = 0, i = 2
tid = 0, i = 3
tid = 0, i = 4
tid = 0, i = 5
tid = 0, i = 6
tid = 0, i = 7
tid = 0, i = 8
tid = 0, i = 9
tid = 1, i = 1
由于我们使用了均匀分配调度策略,每个迭代都会被动态分配给一个线程处理。由于我们有两个线程,所以每个线程将处理 5 次迭代。
通过查看输出,可以发现每个线程都处理了不同的迭代。这是因为动态均匀分配调度策略会动态地将循环划分为若干块,并将块分配给不同的线程。每个线程都会处理它负责的块中的所有迭代,所以迭代是不连续的。(?)
如果是(dynamic,3)则输出是
tid = 0, i = 0
tid = 0, i = 1
tid = 0, i = 2
tid = 0, i = 6
tid = 0, i = 7
tid = 0, i = 8
tid = 0, i = 9
tid = 1, i = 3
tid = 1, i = 4
tid = 1, i = 5
guided

总结
sections制导
Sections制导是OpenMP中的一种控制语句,用于将程序中的一段区域划分为多个部分,并由不同的线程执行。每个部分都包含一个由#pragma omp section指示的代码段,并且只有一个线程会执行一个部分中的代码。使用sections制导时,程序员需要指定线程的数量和每个线程所执行的任务。例如,下面是一个使用sections制导的程序片段:
#pragma omp parallel num_threads(4)
{
#pragma omp sections
{
#pragma omp section
{
// 线程1执行的任务
}
#pragma omp section
{
// 线程2执行的任务
}
#pragma omp section
{
// 线程3执行的任务
}
#pragma omp section
{
// 线程4执行的任务
}
}
}
使用sections制导可以提高程序的并行性和执行效率,但需要注意代码的可读性和可维护性。

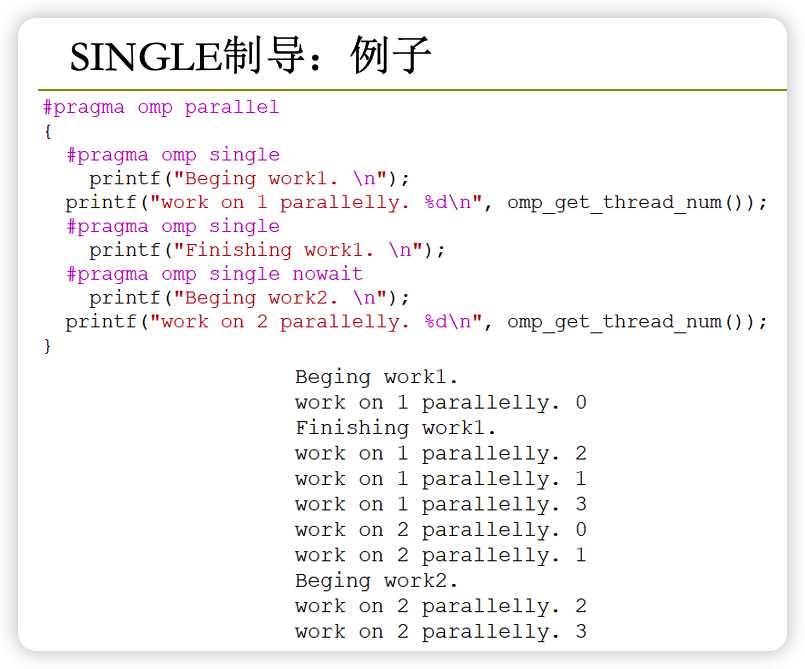
single制导
Single制导是OpenMP中的一种控制语句,用于将程序中的一段代码标记为单线程执行。即只有一个线程会执行single制导指示的代码段,其他线程都会跳过该段代码。使用single制导时,程序员可以指定哪个线程执行该段代码,也可以让编译器自动选择。例如,下面是一个使用single制导的程序片段:
#pragma omp parallel num_threads(4)
{
#pragma omp single
{
// 只有一个线程会执行这段代码
}
}
使用single制导可以确保某些特定的操作只由一个线程执行,从而保证代码的正确性和可读性。但应该尽量避免使用太多的single制导,因为这会减慢程序的执行效率。
作用:
- 为了减少并行域创建和撤销的开销,将多个临近的parallel并行域合并
- 合并后,原来并行域之间的串行代码可以用single指令加以约束只用一个线程来完成
nowait语句
Nowait语句是OpenMP中的一个控制关键字,常用于single制导的语句块中。它的作用是禁止线程在执行完single制导指示的代码段之后等待其他线程。如果没有nowait语句,那么线程会在执行完single语句块之后等待其他线程执行完毕,再继续往下执行。但如果使用了nowait语句,那么线程就会在执行完single语句块之后立即继续执行下一段代码。例如,下面是一个使用nowait语句的程序片段:
#pragma omp parallel num_threads(4)
{
#pragma omp single nowait
{
// 只有一个线程会执行这段代码
// 执行完毕后,该线程立即继续执行下一段代码,不会等待其他线程
}
}
使用nowait语句可以提高程序的执行效率,但应该谨慎使用,以免导致程序错误或不可预测的行为。
master制导
Master制导是OpenMP中的一种控制语句,用于将程序中的一段代码标记为主线程执行。即只有主线程会执行master制导指示的代码段,其他线程都会跳过该段代码。使用master制导时,程序员无需指定哪个线程执行该段代码,因为主线程是固定的。例如,下面是一个使用master制导的程序片段:
#pragma omp parallel num_threads(4)
{
#pragma omp master
{
// 只有主线程会执行这段代码
}
}
使用master制导可以确保某些特定的操作只由主线程执行,从而保证代码的正确性和可读性。但应该尽量避免使用太多的master制导,因为这会减慢程序的执行效率。
barrier制导
Barrier制导是OpenMP中的一种控制语句,用于在并行程序中创建一个同步点,即所有线程在该语句处暂停并等待其他线程完成执行。当所有线程都执行完毕时,才会继续向下执行。例如,下面是一个使用barrier制导的程序片段:
#pragma omp parallel num_threads(4)
{
// 线程1执行的任务
#pragma omp barrier
// 线程2执行的任务
#pragma omp barrier
// 线程3执行的任务
#pragma omp barrier
// 线程4执行的任务
}
上面的程序中,所有线程都会先执行自己的任务,然后在#pragma omp barrier处暂停并等待其他线程执行完毕,最后才会继续往下执行。使用barrier制导可以提高程序的可读性和可维护性,但应该尽量避免在程序中添加太多的同步点,因为这会减慢程序的执行效率。
critical制导
critical制导是OpenMP中的一种控制语句,用于将程序中的一段代码标记为临界区。即只有一个线程会执行critical制导指示的代码段,其他线程都会跳过该段代码。使用critical制导时,程序员需要指定一个名称,用于标识这个临界区。例如,下面是一个使用critical制导的程序片段:
#pragma omp parallel num_threads(4)
{
#pragma omp critical(print_num)
{
// 只有一个线程会执行这段代码,其他线程都会跳过
// print_num是临界区的名称
}
}
使用critical制导可以确保某些特定的操作只由一个线程执行,从而保证代码的正确性和可读性。但应该尽量避免使用太多的critical制导,因为这会减慢程序的执行效率。
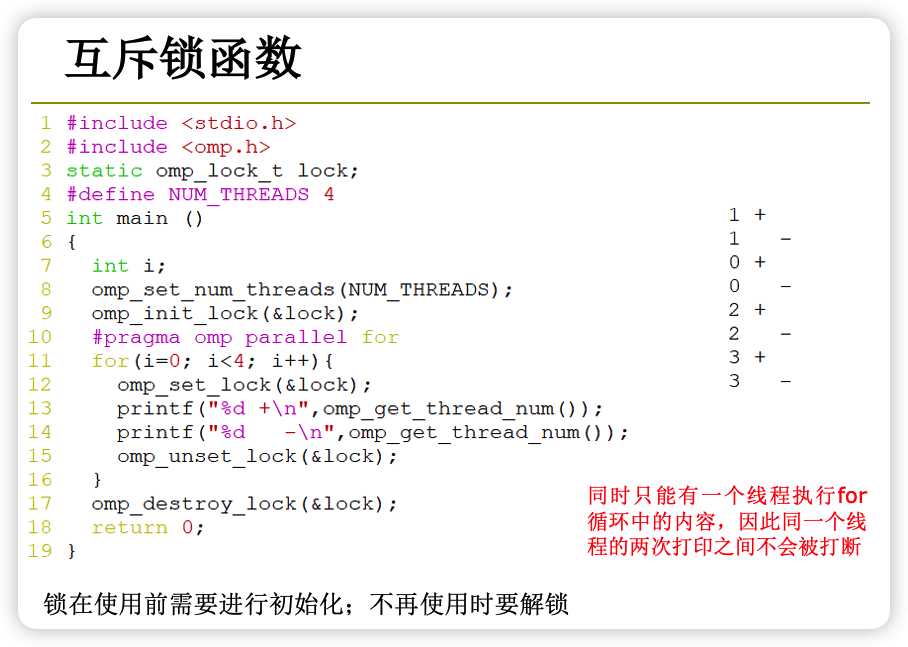
互斥锁函数
锁函数包括omp_unset_lock()、omp_unset_nest_lock()等。
例如,下面是一个使用互斥锁函数的程序片段:
omp_lock_t lock; // 定义一个互斥锁
#pragma omp parallel num_threads(4)
{
omp_set_lock(&lock); // 加锁
// 临界区
omp_unset_lock(&lock); // 解锁
}
上面的程序中,每个线程都会在进入临界区之前加锁,在退出临界区之后解锁。这样,只有一个线程能够执行临界区内的代码,其他线程都会等待。使用互斥锁函数可以保证临界区内的代码串行执行,从而避免并发错误。但应该尽量避免使用太多的互斥锁,因为这会减慢程序的执行效率。
firstprivate子句
firstprivate子句是OpenMP中的一种子句,用于在并行执行某段代码时为每个线程指定一个局部副本。firstprivate子句中指定的变量在并行代码开始时会被每个线程复制一份,在并行代码结束时不会对原始变量进行修改。例如,下面是一个使用firstprivate子句的程序片段:
int a = 1;
#pragma omp parallel firstprivate(a) num_threads(4)
{
a = a + 1; // 每个线程操作的是自己的副本,不会影响原始变量
}
上面的程序中,每个线程都会操作自己的副本,对原始变量a不会产生任何影响。使用firstprivate子句可以简化程序的设计,避免由于并行代码引发的数据竞争问题。但应该谨慎使用firstprivate子句,因为过多的副本可能会增加程序的内存开销。

lastprivate子句
lastprivate子句是OpenMP中的一种子句,用于在并行执行某段代码时为最后一个线程指定一个局部副本。lastprivate子句中指定的变量在并行代码结束时会被最后一个线程的副本覆盖到原始变量上。例如,下面是一个使用lastprivate子句的程序片段:
int a = 1;
#pragma omp parallel lastprivate(a) num_threads(4)
{
a = a + 1; // 每个线程操作的是自己的副本,不会影响原始变量
}
上面的程序中,每个线程都会操作自己的副本,对原始变量a不会产生任何影响。但最后一个线程的副本会被覆盖到原始变量上,使得a的值变为5。使用lastprivate子句可以在并行代码结束后更新原始变量的值,从而简化程序的设计。

加速比、并行效率、可扩展性
并行计算的加速比指的是并行计算与串行计算相比,并行计算能够实现的计算速度提升程度。
并行效率指的是并行计算实际能够利用的处理器数量与所有可用处理器数量的比值,表示了并行计算能够充分利用硬件资源的程度。
可扩展性指的是并行计算在处理器数量增加时,能够保持良好的性能表现的能力。
CUDA&MPI&OpenMP
