
通信粒度
通信粒度是指在分布式计算中,进程之间通信所传递的数据量大小。通信粒度越小,进程之间的通信次数越多,系统的总体效率越低。相反,通信粒度越大,进程之间的通信次数越少,系统的总体效率越高。
通信粒度的大小对分布式计算系统的性能有很大影响。因此,在分布式计算中,通常会对通信粒度进行优化,以提高系统的性能。
数据类型是MPI的一个重要特征,它的使用可有效地减少消息传递的次数,增大通信粒度,并且在收/发消息时避免或减少数据在内存的拷贝、复制。
类型序列和位移序列
一个MPI数据类型由两个$n$元序列构成,第一个序列包括一组数据类型,称为类型序列(type signature):
$$
Typesig=\lbrace type_0, type_1, ..., type_{n-1}\rbrace
$$
第二个序列包含一组整数位移,称为位移序列(type displacements):
$$
Typedisp=\lbrace disp_0, disp_1, ..., disp_{n-1} \rbrace
$$
位移总是以字节为单位计算的。
类型图
$$
Typemap=\lbrace(type_0, disp_0),\cdots,(type_{n-1},disp_{n-1})\rbrace
$$
起始地址设为buff,那么第i块数据为buff+disp_i,类型为type_i,位移不必单调上升,可以为负。


数据类型的上下届与域
数据类型的下界(lower bound)定义为数据的最小位移。数据类型的上界(upper bound)定义为数据的最大位移加1,再加上一个使得数据类型满足操作系统地址对界要求(alignment)的修正量ε。数据类型的域(extent)定义为上界与下界之差:

其中,地址对界修正量 ε 是使得 extent 能被该数据类型的对界量整除的最小非负整数。
一个数据类型的对界量定义如下:原始数据类型的对界量由编译系统决定,而复合数据类型的对界量则定义为它的所有基本数据类型的对界量的最大值。地址对界要求一个数据类型在内存中的(字节)地址必须是它的对界量的整数倍。

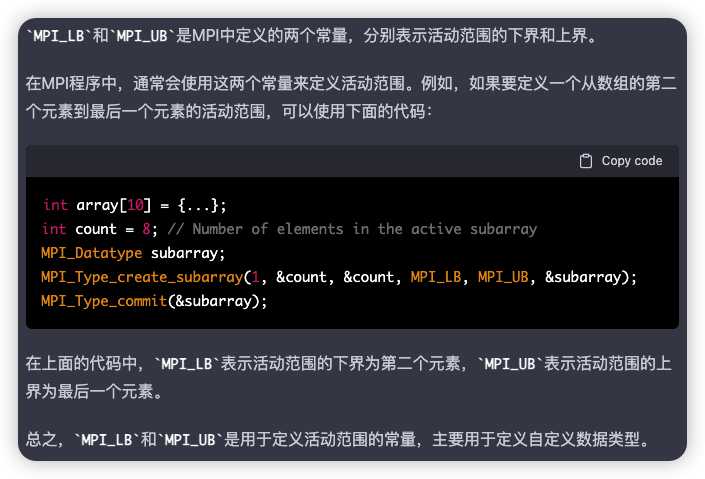
MPI_LB和MPI_UB
它们的作用是让用户可以人工指定一个数据类型的上下界。MPI规定:如果一个数据类型的基本类型中含有 MPI_LB,则它的下界定义为:
$$
lb(type)=min_i\lbrace disp_i | type_i=MPI_{LB}\rbrace
$$
类似地,如果一个数据类型的基本类型中含有 MPI_UB,则它的上界定义为
$$
ub(type)=max_i\lbrace disp_i | type_i=MPI_{UB}\rbrace
$$
数据类型查询函数
- 返回指定数据类型大小:
int MPI_Type_size(MPI_Datatype datatype, int *size) - 返回指定数据类型域:
int MPI_Type_extent(MPI_Datatype datatype, MPI_Aint *extent) - 返回上界:
int MPI_Type_ub(MPI_Datatype datatype, MPI_Aint *displacement) - 返回下界:
int MPI_Type_lb(MPI_Datatype datatype, MPI_Aint *displacement)
数据类型创建函数
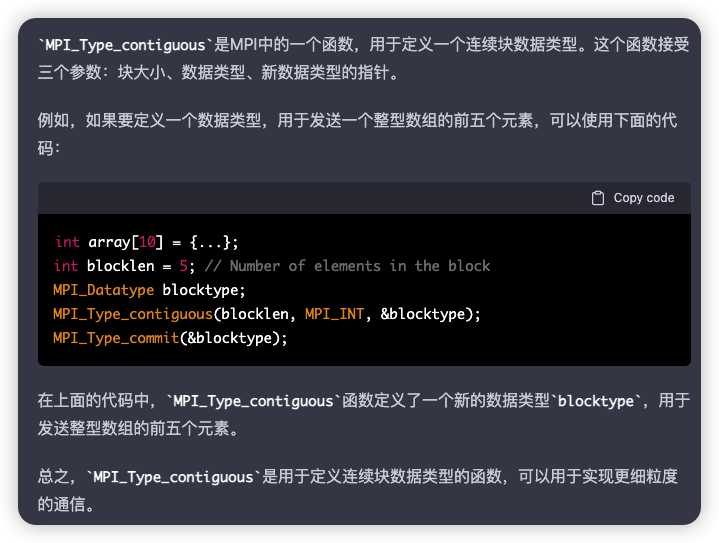
MPI_Type_contiguous
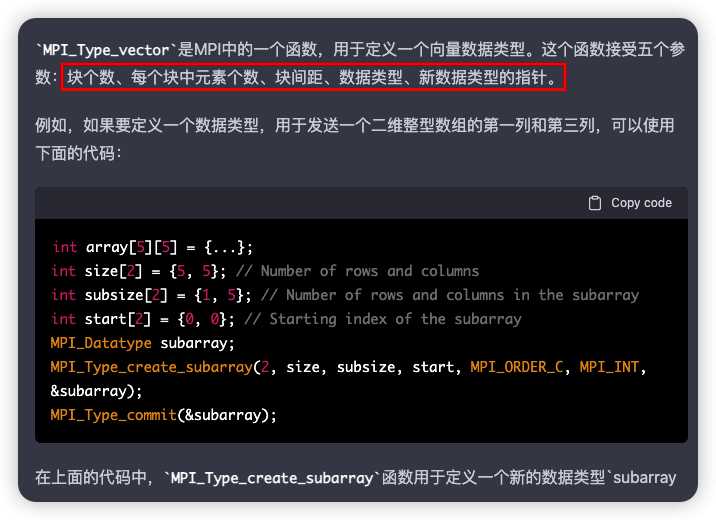
MPI_Type_vector
int MPI_Type_vector(int count, int blocklength, int stride, MPI_Datatype oldtype, MPI_Datatype *newtype
MPI_Type_hvector
函数MPI_Type_hvector与MPI_Type_vector的唯一区别在于stride在MPI_Type_vector中以oldtype的域为单位,而在MPI_Type_hvector中以字节为单位。
MPI_Type_indexed


例1,如果要定义一个数据类型,用于发送一个整型数组的第二个、第四个和第六个元素,可以使用下面的代码:
int array[10] = {...};
int blocks[3] = {2, 4, 6}; // Indices of the blocks
int blocklen[3] = {1, 1, 1}; // Number of elements in each block
MPI_Datatype indexed;
MPI_Type_indexed(3, blocklen, blocks, MPI_INT, &indexed);
MPI_Type_commit(&indexed);
例2,如果要定义一个数据类型,用于发送一个整型数组的第一个、第三个和第五个元素,可以使用下面的代码:
int array[10] = {...};
int blocklen[3] = {1, 1, 1}; // Number of elements in each block
int indices[3] = {0, 2, 4}; // Offset of each block
MPI_Datatype indexed;
MPI_Type_indexed(3, blocklen, indices, MPI_INT, &indexed);
MPI_Type_commit(&indexed);
MPI_Type_hindexed
同上,这个函数是以字节为单位的。

MPI_Type_struct
新数据类型newtype由count个数据块构成,第i个数据块包含array_of_blocklengths(i)个连续存放、类型为array_of_types(i)的数据,字节位移为array_of_displacements(i)。
函数MPI_Type_struct和MPI_Type_hindexed的区别在于各数据块可以由不同的数据类型构成。
数据类型的使用
数据类型的提交:MPI_Type_commit
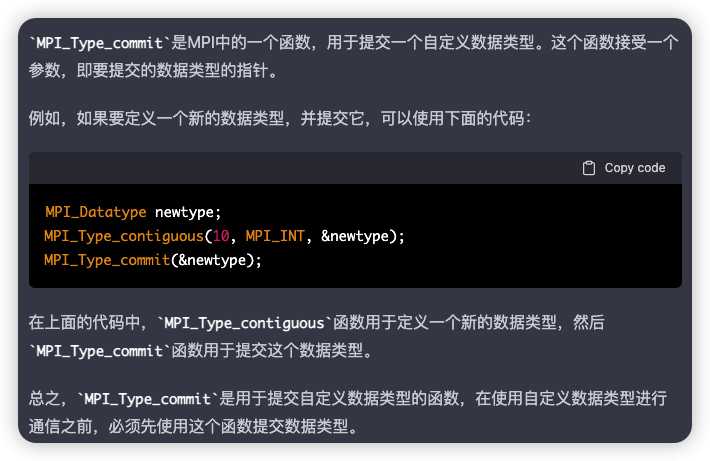
一个数据类型在被提交后就可以和MPI原始数据类型完全一样地在消息传递中使用
数据类型的释放:MPI_Type_free(MPI_Datatype *datatype
其他函数
MPI_Type_size和MPI_Type_extent区别
MPI_Type_size 和 MPI_Type_extent 都是用于获取 MPI 数据类型的大小的函数,但它们有一些区别,如下:
- MPI_Type_size 函数返回的是整型数,表示数据类型的大小。MPI_Type_extent 函数返回的是 MPI_Aint 类型的数据,表示数据类型的大小。
- MPI_Type_size 函数返回的大小是以字节为单位的。MPI_Type_extent 函数返回的大小是以内存中地址的增量为单位的。
一般来说,MPI_Type_size 更常用,因为它返回的是整型数,更容易进行后续的计算。但是,MPI_Type_extent 也有其独特的用途,比如用于表示内存地址的增量等。